
https://openreview.net/forum?id=wfgZc3IMqo
今までの損失関数修正とラベル修正を組み合わせた。その上、回帰問題とみなすことで、shifted Gaussian Label Noise Modelの知見を応用したらしい。
Introduction
古典的な手法(2019以前?)のデータ、損失、ラベルに対してそれぞれ変換を施す手法は次のSurveyにある。
📄![]() 2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
損失関数変換: Noisyなラベルの損失への寄与を減らす。学習の初期では有効だが、正しいラベルが大体訓練された後に、結局Noisy Labelがgradientの主なものを占めて、そこから性能が下がり続けてしまう。だが、学習が有意義であるepochを増やせる。
ラベル変換: Noisyなラベルを正しいと思われるものに変換すること。識別器の判断結果に基づいてRe-labelingするが、
- あまりに早い段階だと識別器自体の訓練が未熟で、正しくRe-labelingできない。
- あまりに遅い段階だと識別器自体がノイズをも記憶してしまい、正しくRe-labelingできない。
この2つを組み合わせてみたよ。つまり、損失関数変換で有効な訓練Epochを引き延ばし、その間で十分にRe-labelingをしてもらうという算段。
後は、分類問題を回帰問題に変換して解いているらしい。
log比変換による組成データ分析
組成データとは
Wikipedia:

意味としては、加算(pertubation)、累乗、内積などを定義している空間である。
次元のVectorについて、すべての成分が非負で、和がである。実質的にVectorは次元であるし、和が固定されているVectorである。
組成データは定義の通りに、制限がかかっているデータであるので、通常の統計的な手法を使用することはできない。
そのままデータの関係性があって、統計的なテク=正規化とかが使えない。何かしらの数学的な変換を施すことで正規化ができるような通常のデータに変換したいというのがモチベ。
ちなみにモチベとしては、Labelの各成分の和が必ず1になるので、それって組成データじゃないか!?ということ。
Log比変換
組成データの各組成の相関情報には、何倍かという量が重要。それを扱うのに
- log比変換で組成データを扱うことで、制限がない普通のデータと同じように見なす。
- 通常の統計的なテクニックを使い、変換した後のデータを見る。
- 逆変換を行って、組成データの世界に戻す。
という流れを提示した。特に組成データの統計モデリングは変換されたデータがLogistic Normal Distributionとなることを仮定している。以下の形の分布らしい。
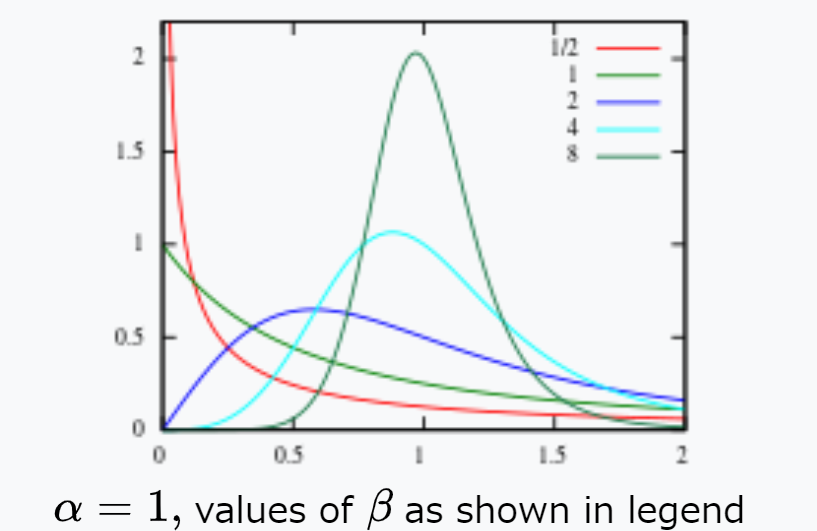
どう変換するのか
組成データから制限がないような空間に変換するのはいろいろあるが、この論文ではlogによる変換に着目する。
Wikipedia:
Additive Log-ratio(alr) transform(加法対数比)
以下のように、例えば最後の要素との比を計算し、対数をとる。割る要素は最後のものではなくてもよく、適当に選べばよい。ただ、非対称性=どのデータを選んだのかによって変換先が結構違ってくる、を持ってしまう。分布が非対称だと、うまく正規化できない。
Centered Log-ratio(clr) transform(中心対数比)
は相乗平均である。
計算を進めてlogをほどくと、以下のようになり、和が0になるという素晴らしい性質がある。つまり変換先も次元であるといえる(和が0という制約が残るので)。なので、とあるが線形空間として同型なのはなのが内実。
そのうえ、幾何平均なので、どのデータを選ぶも何もなく、対称性を持つ。
Isometric Log-ratio(ilr) transform(等距離対数比)
以下のように、最後の要素との比を計算し、対数をとる。は次元の直交基底から本選んで。の行列で、基底変換をしている。これによって、clrで同型でしかなかった線形空間にちゃんと写像できるようになった。
直交基底はグラムシュミットの直交化法でもよいし、幾何的統計的な特徴を考慮して作ってもよい。
Method
全体の流れとしては、
- Label Smoothingを使って、普通のデータを組成データに変換する。
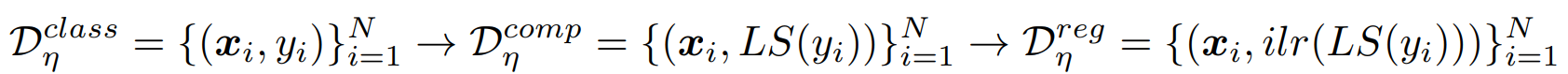
- は回帰に使うデータセットなので、回帰を計算する。ここで、ReweightingとLoss Correctionを両方使った手法にする。
- 回帰の計算結果を、もともとのクラスに戻す。
組成データへの変換
まずはLabel Smoothingを行うことによって、one-hotのラベルをが平均で分散が1の成分で構成されたと混合させる。ここで、と表記したのは、ラベルのone-hotベクトルを組成データとみなしているから。を用いて、以下のようにする。
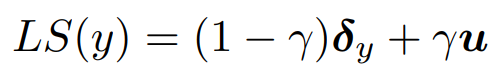
ilr変換を施しているが、行列は、以下のHelmert行列である。
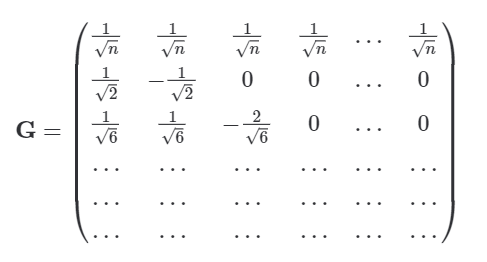
参考: https://www.hello-statisticians.com/explain-terms-cat/helmert1.html#Helmert
1行目はすべてである。2行目以降は、行目ならば個のが続き、最後にはとなる。
使うメリットとしては、計算が簡単、幾何学的な特性やパターンを保持するがノイズを排除しやすい。
これで、となり、のベクトルを得られた。
回帰タスクとして解く
ノイズがあるデータについて、ガウシアンノイズに従うという仮定の下で、最尤推定でを得る。この推定自体をDNNでやったらしい。今までは離散的に扱われていたので、このように連続値のNoiseを足すモデルはなかった。
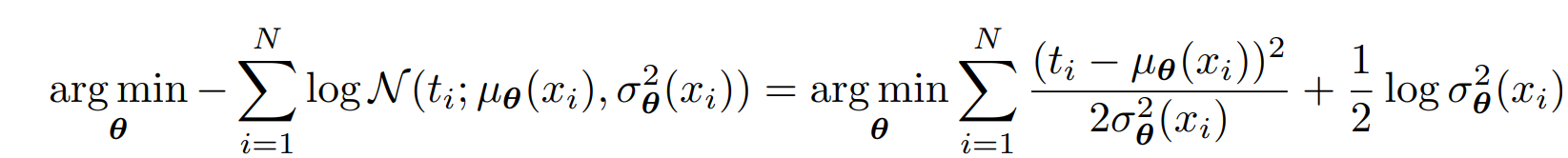
この学習において、シグマの中では各データについて、でReweightingしているといえる(各データごとに軽重をつけているわけではない!)
また、ガウス尤度モデルだと自動で2項目で正則化のような役割を果たすこともできる。
この分布を推定する操作をLoss Reweightingと定義している。なんか、伝統的なReweightingと違くね???
だが、Noisyな環境ではそれだけでは足りないのが現状。そこで、Shifted Noise Modelを提案する。が真のラベルで、観測されるのは。その間のシフトであるを考慮しなければならない。
このを直接推定するのは難しい(それはそう)。代わりに、前に学習したNetworkの重みの指数移動平均=EMAをとることで、変な方向行ってもある程度抑えられるようにさせている。これは先行研究にもあったそのもの。
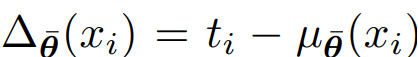
は指数移動平均。つまり学習の式は以下の通り。モデルの指数移動平均版の予測する期待値と、今時点の期待値とのMSEをとる。本来は与えられたNoisyなラベルの位置にあたるものが指数移動平均版の予測する期待値だった。
ただしこの手法では、学習の早い段階ではwarm-upとして、である。は1に近く、はエポック。エポックが大きくなるほど、本来のの式に近づくが、もともとの式では最初では与えられたNoisyなラベルののままにしてる。
回帰の結果を分類に変換
ここまで訓練したことで、分類→回帰で何かしらの予測をすることができた。最後は分類に戻す必要がある。
実験
人工的なノイズの混入は対称的なものと非対称的なもの。4割間違うCIFAR-10とかでも高い性能向上が見られた。
再ラベル付けによる正確性は高レベルな対称ノイズには無力だが、低レベルの対称ノイズではいい結果を挙げている。それでも、対称ノイズに対してロバストな実験結果になっている。